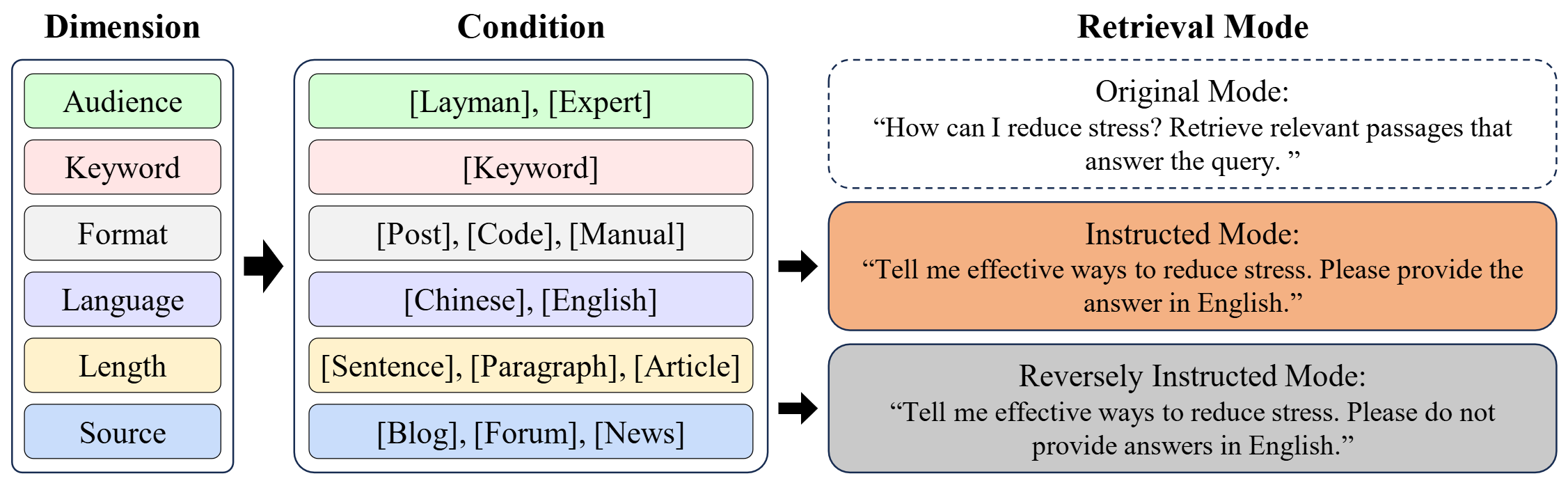
InfoSearch consists of six dimensions, each representing a document-level feature with values drawn from predefined conditions. Queries are paired with one dimension and evaluated in three retrieval modes based on the given instructions.
- Original Mode: This mode serves as a baseline that evaluates the model’s basic retrieval ability to find pertinent information without any specific constraints.
- Instructed Mode: In this mode, the model is required to find documents that are content relevant and satisfy the condition specified in the instruction.
- Reversely Instructed Mode: In this mode, the model is required to find documents that are content relevant and do not satisfy the condition specified in the instruction, which tests the model’s ability to understand negation.